Vision-Language-Action (VLA) Models: A Review of Recent Progress
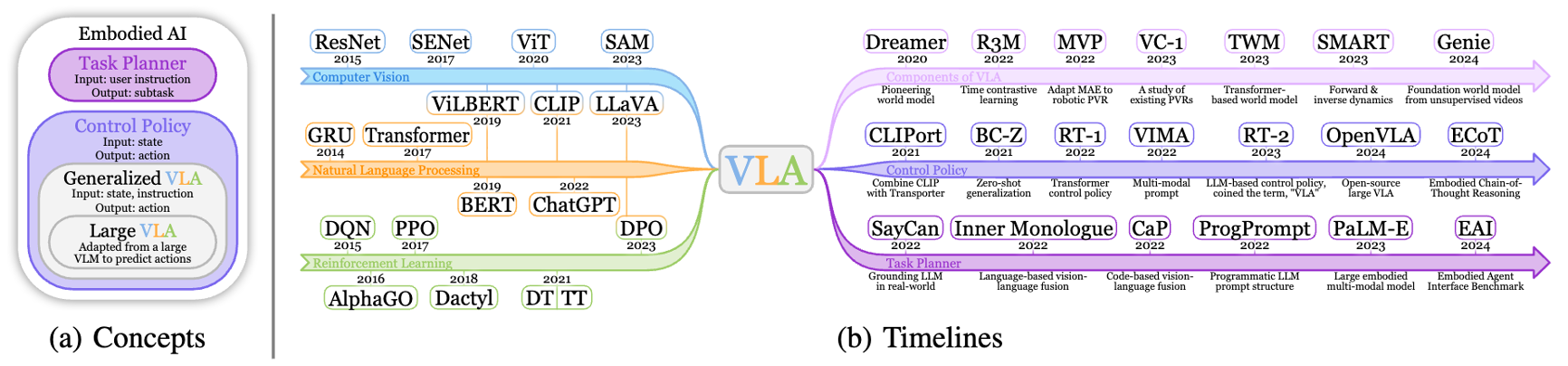
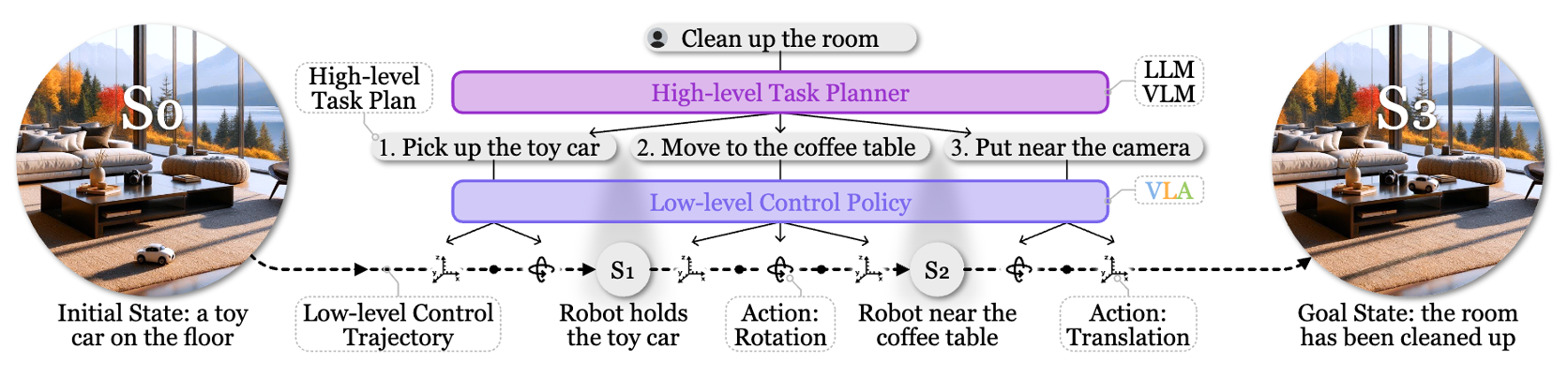
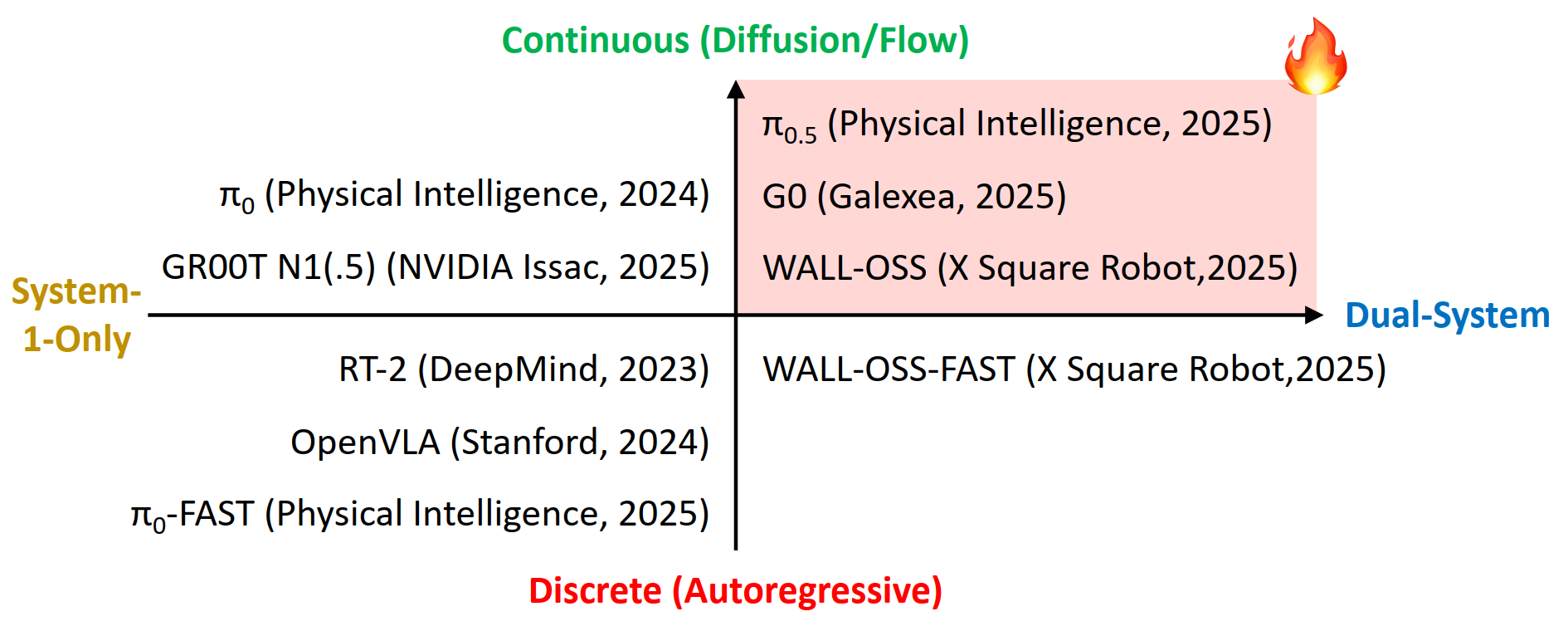
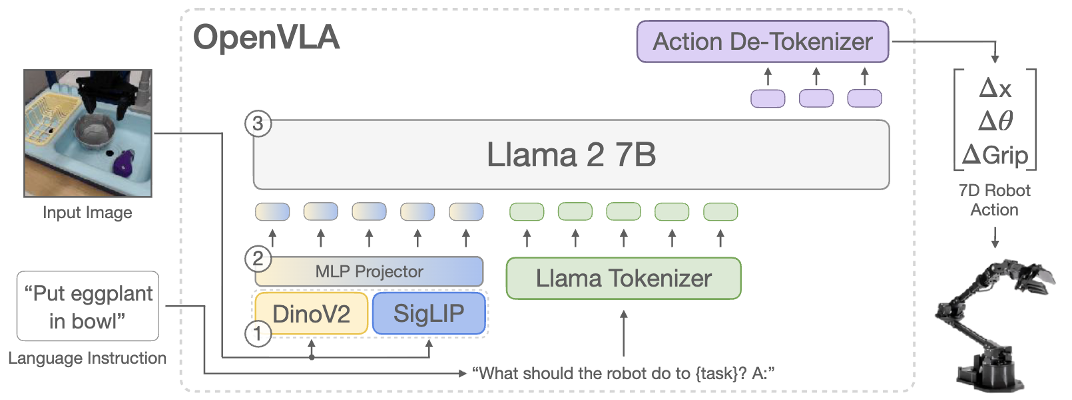
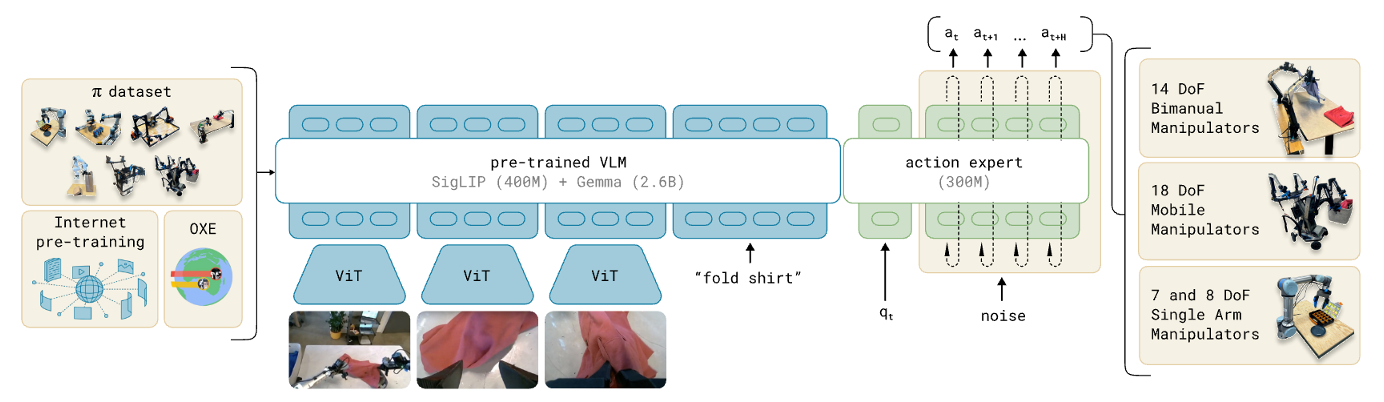
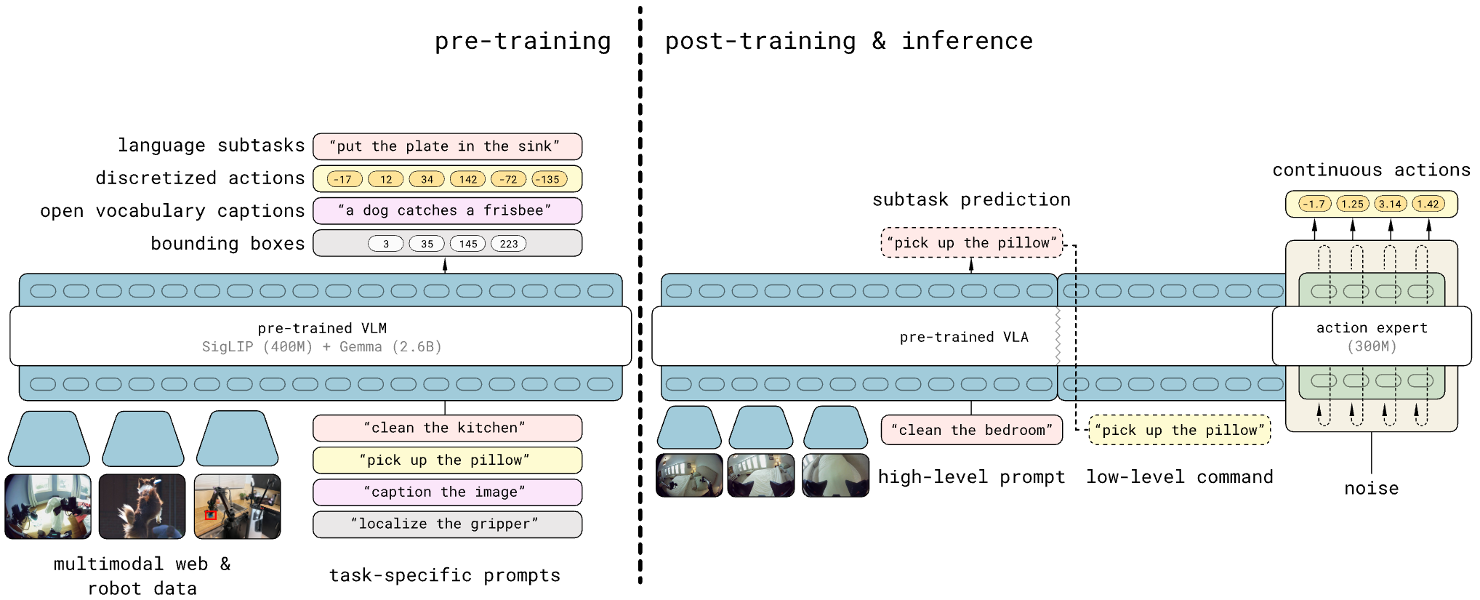
Recent VLAs evolve from discrete to continuous, and from single-system (system 1 only) to dual-system. I am new to this field — feel free to discuss, and welcome to bring up any questions! This is adapted from my slides, available at: [PDF]. According to my understanding, Vision-Language-Action (VLA) Models are multi-modal foundation models for embodied AI, which ingest vision (e.g., observations in video streams) and language (e.g., user instructions) as inputs, and generate low-level robot actions (i.e., the control policy) as outputs. Mechanically, a VLA utilizes a VLM (Vision-Language Model) for VL-conditioned action generation. VLAs are initially optimized for the low-level robot control policy, which is insufficient for completing complex and long-horizon tasks without end-to-end training. An effective approach is to add an LLM/VLM-based task planner to decompose a long-horizon task into simple subtasks, so that the VLA could complete them one by one. While earlier works usually adopt a separate model as the task planner, recent works are utilizing a shared VLM backbone for both task planning and control policy within the same model (i.e., the dual-system design). I summarize the trend of recent VLA as evolving from system-1-only (control) to dual-system (planning + control), and from discrete action to continuous action. I divide recent progress of VLA into 4 quadrants: In the following of this section, I’ll introduce these categories respectively. Discrete VLA generates discrete action tokens. Specifically, it adopts discrete action tokenization that maps low-level robot actions to discrete tokens, and trains the VLM to generate such tokens autoregressively, just like generating text tokens. This provides a straightforward approach to align the two modalities, action and language, which simplifies the training based on autoregressive VLMs (i.e., from next token prediction to next action prediction). However, it suffers from high latency and low FPS in robot control, since the autoregressive generation paradigm needs to go through the entire VLA for each forward pass. Some representative methods: Continuous VLA samples from a continuous action space, which allows smoother control with higher precision, but also increases the difficulty of training atop existing language models. To solve this, Physical Intelligence first proposes to integrate a flow-matching (a variant of diffusion) action expert to a pre-trained VLM, and trains $\pi_0$[4] atop a pre-trained PaliGemma 2B VLM. The insight is to 1) utilize the VLM pre-trained on internet-scale datasets for semantic understanding and generalization, and 2) utilize the flow-matching action expert trained on cross-embodiment datasets for high-frequency (up to 50Hz) control policy. It also allows optional post-training fine-tuning for difficult or unseen tasks. Similarly, NVIDIA Isaac trains GR00T N1(.5)[5] that combines an pre-trained Eagle-2 VLM and an diffusion-based action head, which is the first foundation model for generalist humanoid robots. In both $\pi_0$ and GR00T, the VLM backbone and action expert communicates through attention modules, so that the generated actions are conditioned on the hidden states (i.e., KV) of the VLM. Still, there are two technical differences: Different from earlier works that use a separate LLM/VLM as the task planner (i.e., system-1-only VLA), dual-system VLA utilize the VLM backbone in VLA as the task planner, so the system 2 (high-level planning) and system 1 (low-level control policy) shares one VLM. This further enhances open-world generalization of the VLA, by learning to predict subtasks from user instructions by itself. Besides, it reduces the resource requirements compared to using a separate task planner model. Question: does it also help improve model performance, as the system 1 and 2 are better aligned? On the other hand, does this cause potential interference between different objectives? $\pi_{0.5}$[7] is the first of this category, trained by Physical Intelligence. Compared to $\pi_0$, it involves new training data, including object detection, instructions & subtask commands, discrete actions, etc. At inference time, it first predicts low-level command from high-level prompt with the VLM (system 2), then executes the low-level command with the VLM and action expert (system 1). This paradigm (training recipe and inference scheme) is followed by recent VLA like G0[8] by Galaxea and WALL-OSS[9] by X Square Robot. While most of these models are continuous VLA, WALL-OSS also includes a discrete version with FAST tokenization (WALL-OSS-FAST). Their repositories and open-source states: In the past 3 years (from RT-2 in 2023), VLA has rapidly evolved from discrete to continuous, and from single-system to dual-system. In the following years, I personally think native multi-tasking will be another trend of VLA (I will probably write another post) — embodied agents should be capable of performing multiple fundamentally different tasks (e.g., chat, memory, navigation) instead of restricted to “action”. As introduced above, recent models are already sharing the Internet-scale pre-trained VLM backbone for task planning and control policy (though still restricted to action tasks), which lays the foundation for more aggressive model sharing (one VLM backbone for multiple tasks) as a step forward in the future. I am currently working on building this multi-expert foundation model for native multi-tasking of embodied agents — feel free to contact for discussion and collaboration! Zitkovich, Brianna, et al. “RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control.” Conference on Robot Learning. PMLR, 2023. ↩ Kim, Moo Jin, et al. “OpenVLA: An Open-Source Vision-Language-Action Model.” arXiv preprint arXiv:2406.09246 (2024). ↩ Pertsch, Karl, et al. “FAST: Efficient Action Tokenization for Vision-Language-Action Models.” arXiv preprint arXiv:2501.09747 (2025). ↩ Black, Kevin, et al. “$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control.” arXiv preprint arXiv:2410.24164 (2024). ↩ Bjorck, Johan, et al. “GR00T N1: An Open Foundation Model for Generalist Humanoid Robots.” arXiv preprint arXiv:2503.14734 (2025). ↩ Specifically, the language backbone of the VLM in GR00T N1.5 is fine-tuned from the first 14 layers of the pre-trained Qwen3-1.7B (28 layers in total), according to my test of similarity between the weights. ↩ Intelligence, Physical, et al. “$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization.” arXiv preprint arXiv:2504.16054 (2025). ↩ Jiang, Tao, et al. “Galaxea Open-World Dataset and G0 Dual-System VLA Model.” arXiv preprint arXiv:2509.00576 (2025). ↩ X Square Robot. “WALL-OSS: Igniting VLMs toward the Embodied Space.” 2025, https://x2robot.cn-wlcb.ufileos.com/wall_oss.pdf. White paper. ↩Background and Concepts
The Concept of Vision-Language-Action (VLA) Models
Add VLM-Based Task Planners for Long-Horizon Tasks
Recent Progress of VLA
Discrete VLA
Continuous VLA
Dual-System VLA
Summary and Future Look